Why Contact Targeting Matters
- High Potential Contacts in High Potential Accounts: Identify and target the right contacts within high propensity to buy accounts.
- Humanize the Data: Transition from seeing Accounts as rows in a CRM to identifying the Buying Committee. Use data science to map the specific personas—from the Business User/Influencer to the New Technology Decision Maker.
- Precision Targeting: Stop the “spray and pray” approach by aligning your messaging with the specific pain points of each persona. By predicting which contact is most likely to engage, you can improve targeting precision against the individuals who drive the highest conversion.
- Optimize Multi-Touch Strategy: Design an integrated campaign to hit the right persona at the right time. This ensures that your Account-Based Marketing (ABM) efforts are statistically optimized for the collective decision-making process.
- Contact Data Quality: Proactively maintain key contact coverage, permissions and data quality in high potential accounts.

Introduction & The B2B Modeling Hierarchy
In my experience, B2B contact data lacks the predictive weight found in B2C or subscriber databases. Having managed contact data at Hearst, Cisco, and DellEMC, I’ve seen firsthand that while contact attributes (PII, job titles, and history) are essential for execution, they are often secondary for targeting.
Because contact data is lower in dimensionality and higher in volatility, it rarely contributes to B2B targeting models in a statistically significant way. Even in “greedy” models utilizing 250+ features (including firmographics, purchasing history, competitive install, intent and installed-base telemetrics) the company-level attributes consistently push out contact-level demographics.
Machine learning and statistical algorithms, (such as logistic regression, SVM, Random Forest and XGBoost), will almost prioritize company-level variables, often rejecting contact-level data as “noise” that offers negligible improvement in predictive accuracy.
Starting with the Account
B2B propensity-to-buy (also respond or churn likelihood), RFM or cluster segmentation, and Customer Lifetime Value are all fundamentally based on the company (or account). This has always been the case. To maximize impact, start with the company.
Typically, the most influential variables (features) for these models include:
- Past Purchases (RFM): The strongest indicator of future behavior.
- Recency, Frequency, and Monetary values at the account level provide the historical baseline for any CLV calculation.
- Firmographics: Standardizing variables like Industry and Revenue is critical.
- These act as the primary “branches” in decision-tree models like XGBoost to segment high-value targets.
- Engagement Data: Third-party syndicated media usage and first-party website traffic.
- “Intent” signals, indicate where an account is in the buying journey.
- Pipeline Dynamics: Lead volume and velocity.
- How quickly multiple contacts from the same account are engaging.
- Market Context: Installed base telemetrics (usage) and competitive product footprint.
- Gap analysis of current products that are at maximum use or underutilized for cross-/ up-sell, and identifying accounts that are primed for a displacement campaign based on service contracts or competitive product purchases.
However, once the targeting or segmentation scheme is developed, that is the time that contact penetration, quality and associated attributes become critical for go-to-market execution.
Maintaining a Contact Data Foundation
The foundation for contact data should ideally be in place prior to program execution. This means achieving high contact penetration in key functional areas with established brand awareness and permissions. Because contact data is notoriously volatile, maintenance must be an ongoing process to prevent decay.
Technical Note: For this analysis, I generated synthetic data mirroring a typical B2B tech environment. All data wrangling and modeling were performed using Python (pandas/NumPy) in a Jupyter Notebook, with Matplotlib/Seaborn for graphics and Scikit-Learn for K-Means clustering.
Contact Profiling: Turning Noise into Segments
Marketing to hundreds of thousands of free-form job titles is impossible at scale. To develop a systematic approach, a contact hierarchy is critical. While companies once had to build internal mapping tables, most modern vendors now provide standardized hierarchies to assess quality and facilitate execution.
Start with a demographic profile of contacts currently in the marketing data lake or datamart. The table below is an illustration of a basic contact profiling scorecard that can be used to analyze and track the total marketable contact data foundation.

Addendum: Contact Data Health Checklist
Framework Reference: Forrester (formerly SiriusDecisions) Data Strategy Standards
To ensure the “Workhorse” models discussed in previous articles perform at peak efficiency, I recommend auditing your contact database against these five critical health benchmarks:
- Accuracy: >95% for core predictive features (Job Title, Industry).
- Scientific Impact: High accuracy reduces “label noise” and improves the gain in classification trees.
- Density: 100% completeness for critical path fields (Email, Account Name, Contact Name, Title).
- Scientific Impact: Eliminates data sparsity, ensuring your models don’t rely on biased imputations.
- Timeliness/Validity: <12 months since last verification.
- The Decay Factor: B2B data decays at ~2.1% per month (25% annually). Records older than one year significantly increase bounce rates and skew survival analysis.
- Consistency: 100% standardization on categorical variables (Country, Company Name, Seniority).
- Scientific Impact: Standardizing “US” vs “USA” is essential for Wickham’s (2014) Tidy Data principles and ensures correct feature grouping.
- Buying Group Linkage: >3 contacts mapped per target account.
- Strategic Impact: Essential for moving from individual “Lead Scoring” to “Account-Based Propensity” models.
I wanted to work from a single synthetic dataset to maintain continuity. For the dataset I’ll be using (below), here is a basic job title distribution to use as a starting point and later we will do some basic Persona mapping.

Fitting to the Account Target
Further cross-tabs can be done on the contact data to ascertain whether the contacts exist in high or low potential geographies, industries, etc.
There are three ways to do this. If only a few features are available or a specific industry is being targeted, then match the contacts to the companies:

Once the foundation is set, cross-tabulations can determine if contacts exist within high-potential geographies or industries. We can visualize this through a Tree Map of the top countries and industries. The larger the box, the higher the concentration of a specific job title within that segment.

The “Sweet Spot” for Sales and Marketing
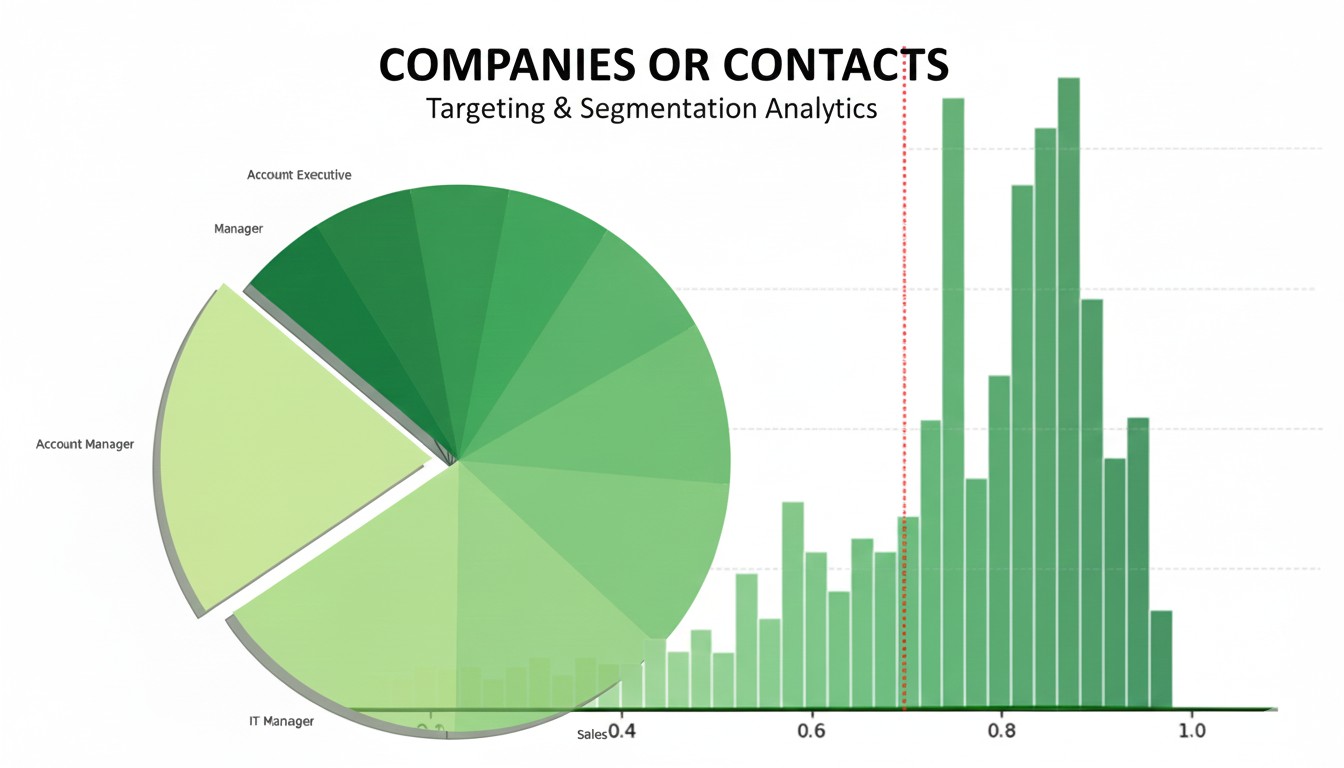
For a synthesized view, we return to the Propensity-to-Buy (P2B) models. By identifying the top job titles within high-propensity accounts, we find the “sweet spot” for marketing spend.

Here we have the top job titles for high-propensity accounts initially in a bar chart (below):

Taking segmentation a step further, we use K-Means clustering to group companies by Industry, Country, and P2B score. According to Tan et al. (2019),
“Cluster analysis groups data objects based only on information found in the data that describes the objects and their relationships. The goal is that the objects within a group be similar or related to one another and different from (or unrelated to) the objects in the other groups. The greater the similarity (or homogeneity) within a group and the greater the difference between groups, the better or more distinct the clustering.”
Tan et al. (2019)
This allows us to drill down into specific personas (e.g., TDMs and Strategic Managers) within “High Value/High Growth” clusters.


Program Execution
Fictitious PII synthetic data to illustrate a final list of contacts in high propensity-to-buy companies. Now the hypothetical program is ready for execution.

Illustration only: synthetic data not intended to represent actual persons or PII.
Conclusion
By prioritizing account fit over contact volume, marketing effectiveness improves across every metric:
- Lower cost-per-lead.
- Higher response rates through relevance.
- Better pipeline quality and higher conversion rates.
- Increased revenue.
Targeting precision in B2B marketing isn’t about how many contacts you reach, but about reaching the right people within the right organizations. Start with the account to find your target, then use high-quality contact data to hit it—this is the most reliable path to maximizing both ROI and market impact.
Citations
Forrester Research. (2024). The B2B Marketing and Sales Data Strategy Toolkit. [Online]. Available at: https://www.forrester.com/report/the-forrester-b2b-marketing-and-sales-data-strategy-toolkit/RES172091
Hoffmann, J. P. (2016). Generalized Linear Models: An Applied Approach (2nd ed.). Routledge.
Integrate. (2025). Implementing the B2B Data Quality Toolkit: Standards for 2026. [Online]. Available at: https://www.integrate.com/resources/b2b-data-quality-toolkit
Miller, T. W. (2015). Marketing Data Science: Modeling Techniques in Predictive Analytics with R and Python. Pearson Education.
Tan, P.-N., Steinbach, M., Karpatne, A., & Kumar, V. (2019). Introduction to data mining (2nd ed.). Pearson Education.
Wickham, H. (2014). Tidy Data. Journal of Statistical Software, 59(10), 1–23. https://doi.org/10.18637/jss.v059.i10
Technical Keywords & Methodology Index
Methodology & Strategy: Account-Based Marketing (ABM) Orchestration, Propensity-to-Buy (P2B) Modeling, Contact-to-Account Mapping, B2B Segmentation Frameworks, Persona Development, Data Health Auditing.
Statistical Concepts: Unsupervised Learning (K-Means Clustering), Feature Engineering (Firmographics vs. Demographics), Dimensionality Reduction, Noise vs. Signal Identification, Classification Tree Logic.
Data Engineering & Operations: Contact Data Health Benchmarking, Data Sparsity Mitigation, Synthetic Data Generation, Tidy Data Principles (Wickham), Database Decay Analysis, CRM Data Normalization.
Revenue Operations (RevOps) Logic: Buying Committee Identification, Pipeline Velocity Optimization, Lead Scoring vs. Account Propensity, Market Coverage Analytics.
Python Libraries & Documentation
For analysts and engineers building a B2B targeting foundation, the following stack maps data science tools to the specific RevOps goals of persona segmentation and account health.
| Library | Role in Pipeline | Strategic Purpose |
| Pandas / NumPy | Data Wrangling | Manages the heavy lifting of CRM data, normalizing disparate firmographic and contact-level features. |
| Scikit-Learn | Predictive Modeling | Executes K-Means clustering to identify high-value/high-growth personas and segments within the contact lake. |
| Seaborn / Matplotlib | Data Visualization | Generates tree maps and scorecard visualizations to translate complex clustering outputs for stakeholder alignment. |
| SciPy | Statistical Analysis | Supports the underlying matrix operations for grouping companies by industry/geography. |
Leave a Reply