The Problem: Beyond the “3+ Rule”: It is widely accepted that a synergistic media mix will always outperform a single media vehicle. Historically, the industry adhered to the “3+ rule”—popularized in the 1970s—which suggested that three exposures to a message were required to influence a purchase. In the digital age, however, that threshold has risen to a frequency of 7+ or more. While media and advertising agencies have used techniques like linear programming and mainframe-based syndicated survey data since the 1980s to optimize these mixes, modern integrated marketing campaigns require a more sophisticated touch.
The Implementation Gap: Throughout my career, my data science teams and I have built media mix optimization models for numerous B2B companies. While these models are often adopted in principle at the executive level, they frequently prove too complex for practical implementation. Often, marketing groups remain so tactically focused that executing a systematically integrated campaign feels unfeasible, rendering the optimization an “academic exercise.” Although modern vendors provide multi-touch attribution (MTA) methods to track touches against opportunities and allocate budgets, the real value lies in using this data as a foundation for deeper optimization work.
A Strategic Priority for the CMO: In practice, CMOs—such as Todd Forsythe and Jonathan Martin—leverage these models to calibrate marketing budgets and enhance overall effectiveness. Building a media mix model is typically the first task I undertake when launching a new data science practice. It is a baseline expectation that a CMO understands the optimal mix for generating pipeline and revenue and allocates their budget accordingly.
Innovation through Association Rules: My approach to media mix modeling has evolved toward leveraging association analysis. The idea originated from Ling (Xiaoling) Huang, and I refined the methodology through collaborations with Yexiazi (Summer) Song and, most recently, Fuqiang Shi, to develop models for diverse business units.
According to Miller (2015), this technique is commonly referred to as Market Basket Analysis, a concept born in retail:
“Market basket analysis, (also called affinity or association analysis) asks, what goes with what? What products are ordered or purchased together?”
By applying this retail-focused logic to media, we can uncover the hidden relationships between marketing channels. As Zhao et al. (2019) noted:
“The challenge of multi-channel attribution lies not just in identifying the final touchpoint, but in uncovering the hidden synergies where the presence of one marketing stimulus significantly amplifies the effectiveness of another.”
Zhao et al. (2019)
The Data: Constructing a Hybrid Marketing Funnel
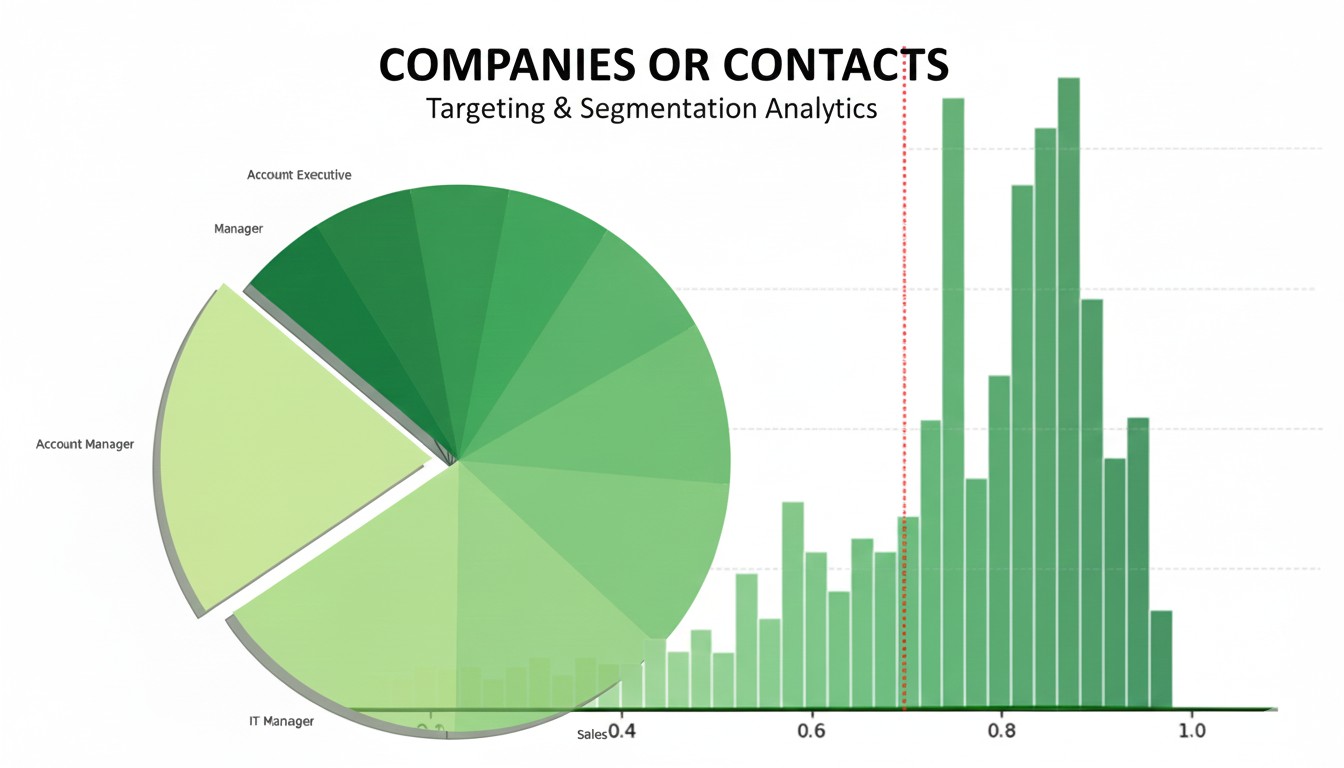
To demonstrate this methodology, I synthesized a consolidated dataset of over 45,000 interactions by merging the UCI Bank Marketing Dataset with the Kaggle/Criteo Multi-Touch Attribution (MTA) Dataset. While these sources represent different industries—fixed-term bank deposits and e-commerce—their combination provides a comprehensive view of the modern buyer’s journey, blending high-frequency digital touchpoints with high-touch personal outreach.
Dataset Profiles
1. UCI Bank Marketing Dataset
This dataset is famous for being highly imbalanced, which is a “real-world” marketing scenario.
- Non-Converters: About 88% of the rows. Customers who were called but did not subscribe to the term deposit.
- Converters: About 12% of the rows.
- Why it matters: Because most people don’t convert, when the model finds a channel like Mobile Outreach that has a high Lift, it’s mathematically significant.
2. Kaggle/Criteo Attribution Dataset
This dataset is designed for Multi-Touch Attribution (MTA).
- Non-Converters: These are “Journeys” where a user clicked on ads (Email, Display, etc.) without converting to a sale.
- Converters: Customer journeys that resulted in sales.
- Why it matters: this helps improve marketing effectiveness and efficiency by identifying waste (channels that people click on but never lead to a sale).
Data Preprocessing
Raw data labels were standardized into a unified “Media Mix” master dataframe to ensure consistency across sources:
- (Kaggle MTA) Email Nurture: Represents the high-volume digital baseline.
- Cellular (UCI Bank Mkt.) Mobile Outreach: Represents direct personal contact via mobile.
- Telephone (UCI Bank Mkt.) Telemarketing: Represents landline-based outreach.
The preprocessing phase involved concatenating the sources, indexing, removing non-essential characters, and handling missing values. I then formatted the dates and standardized the channel categories to enable a seamless cross-platform analysis.
The Data: A Hybrid Funnel Approach
By merging these records, we are modeling a hybrid B2C customer journey. This reflects the reality of high-value industries like financial services, where a customer might be prompted by a high-volume digital ad (Criteo) but requires a personal, high-touch mobile conversation (UCI) to finalize a complex transaction.
This balanced view allows the association rules to uncover synergies across the entire funnel, rather than looking at digital or offline channels in isolation.

Apriori Methodology
Using the Apriori Algorithm (Raschka, 2018, Agraval et al. 1996), I processed over 45,000+ interactions to identify Synergy Lift which is one of several measures of impact. According to Miller (2015) “an association rule is a division of each item set into two subsets with one subset, the antecedent, thought of as preceding the other subset, the consequent. The Apriori algorithm … deals with the large numbers of rules problem by using selection criteria that reflect the potential utility of association rules.” Essential the rule is Antecedent (marketing mix) à Consequent (conversion). Here are the key measures:
- Support (scale) how often this mix occurs:
- Support = occurrences of rule (mix+conversion) / total customer base
- Confidence (predictability) how often a customer buys when exposed to this mix:
- Confidence = ratio of conversions for each media mix combination.
- Lift (synergy) how well this mix performs vs. the average:
- Lift = Confidence/Support (consequent or avg. conversion rate)
Model Output
Once I ran the Apriori algorithm and selected the top rules by highest lift (mix performance vs. the average) it was clear that the volume of marketing interaction was not aligned to conversion potential. The chart below has to be interpreted with caution, and illustrates the danger of looking at any channel in isolation, because email looks high volume/ low lift however it often occurs in high-potential integrated combinations.

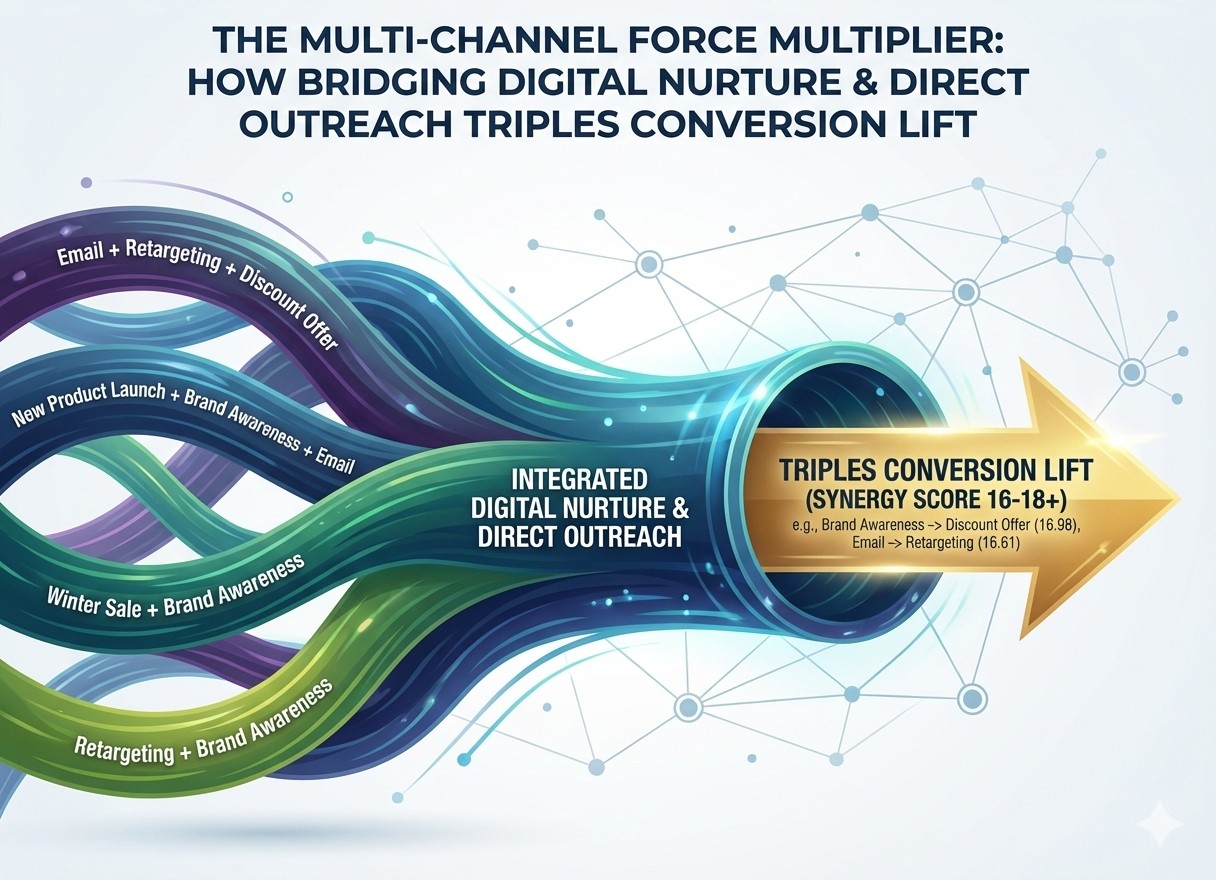
Lift (>1) is the force multiplier and so that is how I evaluated the combinations for effectiveness in converting customers. For example, many combinations without mobile, direct mail, email and telemarketing had high impact. Activities that happen on the right-hand side of the arrows (>>) are happening at the same time as the customer conversion (Converted), and so should be considered part of the overall mix.
New product launches, combined with brand awareness, email and retargeting had the most impact, followed by a similar mix that replaced launches with discounting – both are time sensitive calls to action and so this makes sense. Activities on the left-hand side of the arrows are typically the ‘nurture’ phase while the right-hand side is the conversion event.

This visual shows the top media mix combinations and their performance relative to the baseline. So, for a financial services marketer this would be the roadmap for funding and executing integrated marketing campaigns:

If we want to look at combinations to check a particular pair of marketing channels, or create a particular tactic, a correlogram like the one below shows the pairs with the most lift.

Optimizing Marketing Budgets: A Data-Driven Approach
From a funding perspective, analyzing our 55,211-record blended dataset through Ridge regression allows us to move beyond raw interaction volume to true contribution. By generating and normalizing beta coefficients, we can isolate the unique impact of each channel on the final conversion event, providing a mathematical foundation for marketing spend allocation.
Based on this specific analysis, here is the performance breakdown of the primary drivers and their normalized contribution to conversion:

Summary
- The Efficiency of Retention: Email and Referral show the highest normalized contribution ($~20\%$ each), suggesting that “warm” audience paths are the most reliable foundation for the budget.
- The Synergy Mandate: Funding should prioritize synergistic pairs rather than siloed channels. For example, the high weights of Social Media and Search Ads suggest they function best when funded in tandem to capture both interest and intent.
- Awareness as Air-Cover: “Brand Awareness” channels (Social/Display) provide the necessary air-cover for time-sensitive, high-conversion calls to action like New Product Launches and Discount Offers.

Citations:
Criteo Labs (2018). Criteo Attribution Modeling & Bidding Dataset. Kaggle. Available at: https://www.kaggle.com/c/criteo-attribution/data
Miller, T. W. (2015). Marketing Data Science: Modeling Techniques in Predictive Analytics with R and Python. Pearson Education.
Moro, S., Cortez, P., & Rita, P. (2014). A Data-Driven Approach to Predict the Success of Bank Telemarketing. Decision Support Systems, 62, 22-31. Elsevier. https://doi.org/10.1016/j.dss.2014.03.001
Raschka, S. (2018). MLxtend: Providing machine learning and data science utilities and extensions to Python’s scientific computing stack. Journal of Open Source Software, 3(24), 638. https://doi.org/10.21105/joss.00638
Zhao, K., et al. (2019). Deep Learning and Association Rules for Multi-Channel Attribution. In Proceedings of the 2019 International Conference on Data Mining & Marketing Analytics.
UCI Machine Learning Repository. (2012). Bank Marketing Dataset. https://archive.ics.uci.edu/ml/datasets/Bank+Marketing